Pourquoi est-ce si compliqué de lire ses propres notes sur une liseuse ?
Personne ne se réveille en se disant "tiens, aujourd'hui je vais coder un convertisseur markdown vers ePub". Sauf moi.


Imaginons la scène. On passe des heures à structurer ses idées dans Notion. On organise, on lie, on construit une base de connaissances qui commence enfin à ressembler à quelque chose. Markdown partout, propre, versionnable, exportable.
Et puis arrive le moment où on veut simplement... les lire. Tranquillement. Sur une liseuse.
Spoiler : ça ne marche pas comme prévu.
Les fichiers markdown exportés s'ouvrent en vrac. Les images disparaissent. La mise en page ressemble à un accident typographique. Une Kindle affiche un mur de texte sans structure. Une Supernote Nomad fait ce qu'elle peut, mais le résultat est tristement basique.
Le format ePub existe. Les liseuses le supportent. Mais entre un markdown propre et un ePub lisible, il y a un gouffre technique que les outils existants ne comblent qu'à moitié.
C'est exactement ce gouffre que md_to_epub vient combler.

Avec du pair programming avec Claude Code.
Ce projet a également été l'occasion d'expérimenter avec Claude Code en mode pair programming. Avoir un assistant IA pour challenger les choix d'architecture, suggérer des optimisations de code, et déboguer les cas limites a accéléré le développement tout en maintenant la qualité. J'apporte les idées, les tests, l'architecture, les besoins, les restrictions ... et j'avance en binôme.
Le solo coding n'est plus vraiment solo. Et c'est tant mieux.
Anatomie d'un besoin réel
Parlons vrai. Personne ne se réveille en se disant "tiens, aujourd'hui je vais coder un convertisseur markdown vers ePub". Moi y compris. J'ai mentis plus haut. C'est le genre de projet qui naît d'une accumulation de micro-frustrations.
La situation de départ :
- Des dizaines de notes Notion en markdown
- Plusieurs liseuses différentes (Kindle, Supernote, Kobo, etc.)
- Un objectif simple : lire ses propres notes comme de vrais livres numériques
- Des solutions existantes soit trop complexes, soit trop limitées
Les tentatives ratées :
Première tentative avec Calibre. Puissant, mais lourd. Pour convertir un fichier, il faut l'importer, configurer les métadonnées, ajuster le CSS, exporter. Répéter ça pour une dizaine de fichiers ? L'enfer.
Ensuite, les convertisseurs en ligne. Pratiques pour un fichier unique, catastrophiques pour du traitement par lot. Sans parler de la gestion des images ou des métadonnées.
Et la sécurité des données ?
N'en parlons même pas.
Pandoc directement ? Excellent outil, mais la ligne de commande devient vite un cauchemar quand on veut fusionner plusieurs fichiers avec des métadonnées cohérentes.
La vraie question :
Pourquoi est-ce si compliqué de transformer du texte structuré en livre numérique lisible ?
La réponse courte : parce que personne n'a construit l'outil avec le workflow utilisateur en tête. En général, on s'est concentré sur la conversion technique, pas sur l'expérience. C'est pas grave, mais c'est juste chiant parfois.
La solution : penser workflow avant technologie
Le principe de conception
Un bon outil doit disparaître. L'utilisateur ne devrait pas avoir à réfléchir à comment l'outil fonctionne, mais à ce qu'il veut accomplir.
Pour md_to_epub, j'ai défini cinq cas d'usage clairs :
- Convertir un fichier unique → tu as un article, tu veux un ePub. Point.
- Fusionner plusieurs fichiers → tu as des chapitres séparés, tu veux un seul livre.
- Convertir un dossier entier → tu as une collection de notes, tu veux un ePub par fichier.
- Fusionner tout un dossier → tu as un projet documenté, tu veux un seul ePub compilé.
- Traitement récursif → parce que parfois, tes fichiers sont organisés en sous-dossiers.
Chaque mode répond à un besoin spécifique. Pas de feature bloat, pas de configuration obscure. Juste les options qui comptent.
L'interface : quand le terminal devient accueillant
Petit détour pédagogique : c'est quoi un CLI ?
CLI signifie "Command Line Interface", ou interface en ligne de commande en français. Contrairement aux applications graphiques où on clique sur des boutons, un CLI s'utilise en tapant des commandes textuelles dans un terminal (cette fenêtre noire qui fait peur aux débutants).
Avantages :
- Automatisation facile (scripts)
- Consommation mémoire minimale
- Contrôle précis des paramètres
- Reproductibilité (on peut rejouer exactement la même commande)
Inconvénient :
- Courbe d'apprentissage abrupte
- Il faut mémoriser les commandes et leurs options
La ligne de commande fait peur. C'est un fait. Mais elle reste l'outil le plus efficace pour automatiser des tâches.
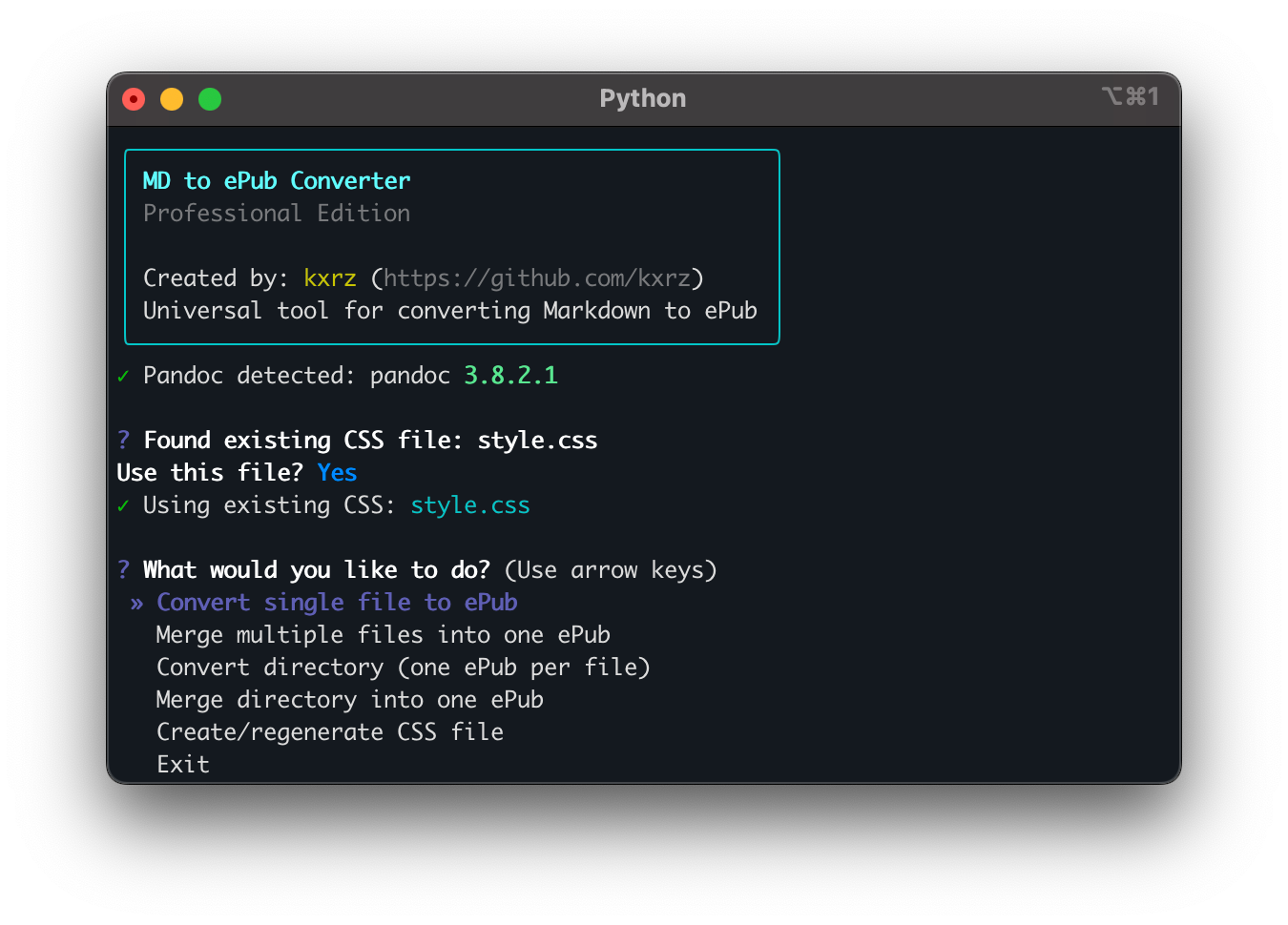
La solution ? Un menu interactif qui guide l'utilisateur :
┌─────────────────────────────────────────────────┐
│ MD to ePub Converter │
│ Professional Edition │
│ │
│ Created by: kxrz (https://github.com/kxrz) │
│ Universal tool for converting Markdown to ePub │
└─────────────────────────────────────────────────┘
? What would you like to do?
❯ Convert single file to ePub
Merge multiple files into one ePub
Convert directory (one ePub per file)
Merge directory into one ePub
Create/regenerate CSS file
Exit
Plus besoin de se souvenir des flags --dir, --merge, --recursive. L'outil pose les bonnes questions au bon moment.
Et pour ceux qui veulent automatiser ? La CLI classique reste disponible :
python md_to_epub.py document.md --author "Your Name"
python md_to_epub.py --dir ./chapters --merge --title "My Book" --author "Your Name"
Le meilleur des deux mondes.
Le CSS : l'obsession invisible
Aparté technique : CSS, ePub et liseuses
CSS (Cascading Style Sheets) est le langage qui définit l'apparence visuelle d'un document électronique : polices, couleurs, espacements, mise en page. Dans un ePub, le CSS détermine comment le texte s'affiche sur la liseuse.
Le problème ? Chaque liseuse interprète le CSS différemment :
- Kindle utilise son propre moteur de rendu avec des limitations
- Kobo supporte mieux les standards ePub
- Apple Books a ses propres spécificités
- Les liseuses Android varient selon le lecteur installé
Résultat : un ePub peut être magnifique sur une Kobo et illisible sur une Kindle.
Voici un truc que personne ne remarque quand c'est bien fait, mais que tout le monde subit quand c'est raté : la typographie sur liseuse.
Le CSS inclus dans md_to_epub est le résultat de tests sur plusieurs appareils :
Typographie :
- Georgia pour le corps de texte (excellente lisibilité sur e-ink)
- Helvetica pour les titres (contraste visuel net)
- Fallbacks système pour garantir l'affichage
Optimisations e-reader :
- Sauts de page automatiques sur les H1 (nouveaux chapitres)
- Hyphenation intelligente pour éviter les mots coupés n'importe comment
- Marges et espacements pensés pour l'écran 6 pouces
Gestion des éléments :
- Blocs de code avec police monospace et background subtil
- Citations avec bordure bleue et italique
- Images responsives qui s'adaptent à la largeur d'écran
- Tables lisibles même sur petit écran
Résultat : un ePub qui ressemble à un vrai livre numérique, pas à un export brut.
Les métadonnées : le détail qui change tout
C'est quoi le YAML frontmatter ?
Le YAML frontmatter est un bloc de métadonnées placé au tout début d'un fichier markdown, délimité par trois tirets (---). Il permet d'ajouter des informations structurées (titre, auteur, date, etc.) sans polluer le contenu principal.
Exemple :
---
title: Mon super article
author: Jean Dupont
date: 2025-10-27
---
# Début du contenu
Mon texte commence ici...
C'est un standard utilisé par de nombreux outils : Jekyll, Hugo, Obsidian, Notion (à l'export), etc.
Un ePub sans métadonnées, c'est comme un livre sans couverture. Techniquement lisible, mais l'expérience est bancale.
md_to_epub gère deux approches :
YAML frontmatter dans le fichier markdown :
---
title: Guide complet de la conversion markdown
author: Votre Nom
description: Tout ce qu'il faut savoir pour créer des ePub professionnels
lang: fr
date: 2025-10-27
publisher: Auto-édition
---
Saisie interactive lors de la conversion :
L'outil détecte automatiquement un titre depuis le nom de fichier, mais permet de l'éditer. L'auteur est obligatoire (un ePub sans auteur, c'est mal foutu). Les autres champs sont optionnels mais recommandés.
Pourquoi c'est important ? Parce qu'une liseuse utilise ces métadonnées pour trier, rechercher, et afficher les livres. Un ePub bien tagué s'intègre naturellement dans une bibliothèque.
Les cas d'usage concrets
Scenario 1 : le blogueur qui compile
Cas typique : on écrit des articles de blog en markdown. On veut créer un recueil annuel des meilleurs posts.
Workflow :
- Export des articles depuis le CMS (Ghost, Hugo, Jekyll...)
- Lancement de md_to_epub en mode interactif
- Sélection "Merge multiple files into one ePub"
- Choix des articles dans l'ordre souhaité
- Ajout du titre, auteur, description
- Récupération de l'ePub prêt à partager
Temps total : 2 minutes.
Scenario 2 : le maker qui documente
Cas typique : on crée des projets DIY. On documente tout en markdown avec photos. On veut offrir un ePub téléchargeable sur son site.
Workflow :
- Organisation des fichiers markdown par projet
- Placement des images en relatif (
./images/schema.jpg) - Commande
python md_to_epub.py --dir ./projet_domotique --merge --author "Nom" - L'outil fusionne tout, embarque les images, génère la table des matières
- Upload de l'ePub sur le site
Bonus : les images sont automatiquement intégrées dans l'ePub. Pas de liens cassés, pas de dépendances externes.
Scenario 3 : l'étudiant qui révise
Cas typique : on prend des notes de cours en markdown. On veut les lire sur sa liseuse dans le train.
Workflow :
- Export des notes depuis Notion, Obsidian, ou Joplin
python md_to_epub.py --dir ./notes_informatique --author "Moi"- Transfert des ePub sur la Kindle par USB
- Révisions optimisées en déplacement
Avantage : un ePub par matière, navigation fluide entre les chapitres, pas de distraction (contrairement à un écran d'ordinateur).
Scenario 4 : l'auteur qui autopublie
Cas typique : on écrit un livre. Chaque chapitre dans un fichier markdown séparé. On veut un ePub professionnel pour Amazon KDP ou Kobo Writing Life.
Structure recommandée :
mon_livre/
├── 00_frontmatter.md
├── 01_introduction.md
├── 02_chapitre_un.md
├── 03_chapitre_deux.md
├── 04_chapitre_trois.md
├── 99_backmatter.md
└── images/
├── cover.jpg
└── diagram_01.png
Workflow :
- Mode interactif : "Merge directory into one ePub"
- Sélection du dossier
- Les fichiers sont fusionnés dans l'ordre alphabétique (d'où les préfixes numériques)
- Métadonnées complètes avec ISBN si besoin
- ePub prêt pour validation Kindle Previewer ou Calibre
Résultat : un fichier professionnel avec table des matières cliquable, chapitres bien séparés, images en haute résolution.
Les choix techniques qui font la différence
Pandoc : le moteur invisible
md_to_epub s'appuie sur Pandoc, l'outil de référence pour la conversion de documents. Pourquoi ne pas coder un parser markdown from scratch ?
Parce que Pandoc gère déjà :
- Tous les dialectes markdown (CommonMark, GitHub Flavored, MultiMarkdown...)
- Les extensions complexes (tables, footnotes, définitions...)
- La génération d'ePub conforme aux standards
Réinventer la roue aurait été une perte de temps. md_to_epub ajoute la couche UX et workflow que Pandoc ne fournit pas.
Python : rapidité et portabilité
Python pour un outil CLI ? Absolument.
Avantages :
- Ecosystème riche (questionary pour les menus, rich pour l'affichage, PyYAML pour les métadonnées)
- Portabilité (fonctionne sur macOS, Linux, Windows)
- Facilité de contribution (tout développeur Python peut améliorer le code)
- Pas de compilation nécessaire
Dépendances minimales :
- questionary : menus interactifs
- rich : affichage élégant dans le terminal
- PyYAML : parsing des métadonnées
- python-frontmatter : extraction du YAML depuis les fichiers markdown
Installation en une ligne : pip install -r requirements.txt
Architecture modulaire
Le code est structuré autour d'une classe principale EpubConverter qui encapsule toute la logique de conversion. Les fonctions sont courtes, testables, et séparent clairement les responsabilités :
- Détection et validation des fichiers
- Extraction des métadonnées
- Gestion du CSS
- Appel à Pandoc avec les bons paramètres
- Gestion des erreurs et messages utilisateur
Résultat : un code maintenable qui peut évoluer facilement.
Ce que la construction de cet outil a révélé
1. L'UX compte, même dans un terminal
Il existe une idée reçue selon laquelle la ligne de commande serait réservée aux experts qui n'ont pas besoin de guidage. C'est faux.
Un bon CLI doit être aussi accueillant qu'une interface graphique. Les menus interactifs, les barres de progression, les messages d'erreur clairs... tout ça compte.
Questionary et Rich transforment radicalement l'expérience. Comparaison :
Avant :
$ python convert.py file.md
Error: missing author
Après :
✗ Missing required field!
→ Author name cannot be empty
? Please enter author name: _
La différence est subtile mais massive en termes d'utilisabilité.
2. Les détails CSS font toute la différence
Le CSS pour e-reader a nécessité plus de temps que la logique de conversion elle-même. Pourquoi ?
Parce qu'un ePub techniquement correct mais moche est inutilisable. Les gens ne lisent pas des fichiers, ils lisent des expériences.
Le CSS pour e-reader a ses propres règles :
- Pas de
position: absolute(ignoré par la plupart des liseuses) - Pas de fonts externes (trop lourd, incompatibilité)
- Attention aux
marginetpadding(les écrans e-ink ont des DPI différents) - Toujours tester sur plusieurs appareils
Le CSS a été refait trois fois avant d'atteindre sa forme finale. La troisième version est 30% plus courte que la première, mais deux fois plus efficace (et va sûrement encore évoluer).
3. Le versionning sémantique, c'est pour tout le monde
Même un petit projet personnel mérite des versions propres. md_to_epub est passé de 1.0 (conversion basique sur Gist) à 2.0 (interface interactive, fusion de fichiers sur GitHub) avec un changelog clair.
Pourquoi c'est important ? Parce que d'autres personnes utilisent l'outil. Elles doivent pouvoir comprendre ce qui a changé et si la mise à jour va casser leur workflow.
4. Documentation > Code
Un script Python de 1140 lignes sans README, c'est inutile. Personne ne va lire le code pour comprendre comment l'utiliser.
Le README de md_to_epub fait presque autant de lignes que le code lui-même. C'est voulu. Chaque cas d'usage est documenté avec des exemples concrets. Chaque flag CLI est expliqué. Les erreurs courantes ont leur section dédiée.
Résultat : les utilisateurs trouvent leurs réponses sans avoir à contacter le développeur. Et quand ils contribuent, ils comprennent déjà l'architecture globale.
5. L'open source force la qualité
Savoir que d'autres vont lire son code change tout. On écrit des commentaires plus clairs. On structure mieux. On teste davantage.
md_to_epub est sur GitHub avec une licence permissive. N'importe qui peut l'utiliser, le modifier, le redistribuer. Cette ouverture oblige à maintenir un niveau de qualité élevé.
Et bonus : il y a déjà eu des suggestions d'amélioration. Des cas d'usage auxquels personne n'avait pensé au départ. Des bugs qui n'auraient jamais été détectés en solo.
Merci Reddit !
Les limites assumées
md_to_epub ne fait pas tout. Et c'est voulu.
Ce que l'outil ne gère pas (volontairement) :
- Génération de couvertures automatiques → trop de variabilité, mieux vaut utiliser Canva ou Photoshop
- Conversion ePub vers autres formats → Calibre le fait mieux
- Édition visuelle du contenu → pas le scope, utilisez donc un éditeur markdown dédié
- Hébergement ou distribution → c'est un convertisseur, pas une plateforme
Chaque feature non incluse est un choix conscient. L'outil fait une chose, et la fait bien.
En bref : de l'outil au workflow
md_to_epub n'est pas juste un script Python. C'est une réponse à un problème de workflow.
Le vrai challenge n'était pas technique (Pandoc fait le gros du travail). C'était de concevoir une expérience utilisateur qui rende la conversion markdown → ePub aussi naturelle que d'exporter un PDF.
Le résultat :
- 5 modes de conversion adaptés à des besoins réels
- Une interface qui guide sans infantiliser
- Un CSS optimisé pour liseuses modernes
- Des métadonnées propres pour une intégration fluide
- Une documentation exhaustive pour l'autonomie
Il arrive qu'on veuille lire ses notes Notion sur sa Kindle comme si c'étaient de vrais livres. Avec table des matières, navigation fluide, et typographie agréable.
C'est exactement ce que md_to_epub permet de faire.
Pour ceux qui prennent des notes en markdown, possèdent une liseuse, et en ont marre des conversions foireuses... md_to_epub peut valoir le coup d'essai.
C'est gratuit, open source, et ça fonctionne.
GitHub : github.com/kxrz/md_to_epub



