Flashcards Club : transformer sa liseuse en machine à apprendre
Oui, ceci est mon retour d'expérience du lancement du dernier side-projet qui transforme un prompt en un ebook pour nos liseuses.


Il y a quelques semaines, j'ai eu un truc en tête qui ne me lâchait pas. On passe des heures sur nos liseuses à lire passivement, mais pourquoi ne pas en faire des outils d'apprentissage actif ? Les écrans e-ink ont tout pour ça : confort visuel, concentration, autonomie. Le format EPUB est ouvert et universel. Les flashcards sont une méthode d'apprentissage éprouvée. Il manquait juste le pont entre les trois.

Fin octobre 2025, j'ai commencé à coder Flashcards Club. Le 12 décembre, le site était en ligne. Entre les deux, il y a eu un MVP bancal, des beta testeurs patients, des bugs d'alignement absurdes, et pas mal d'itérations sur un format qui semblait simple au départ mais qui s'est révélé plus retors que prévu.
Cet article raconte ce parcours, de la première version qui générait des EPUB cassés à l'intégration d'un système de paiement one-time avec Stripe. Pas de storytelling lissé, juste le vrai cheminement d'un projet qui part d'une intuition et qui se confronte à la réalité technique.
Pourquoi les liseuses pour apprendre
Avant de parler code, il faut comprendre le problème de départ. Les apps de flashcards traditionnelles (Anki, Quizlet, Memrise) fonctionnent très bien sur smartphone ou ordinateur. Elles ont des interfaces léchées, des systèmes de répétition espacée sophistiqués, des stats détaillées. Mais elles héritent aussi des défauts de ces supports.
Sur smartphone, tu es à trois secondes d'une notification. Tu révises du vocabulaire anglais, un message arrive, tu réponds, tu scrolles Instagram par réflexe, et tu as perdu le fil. La concentration est fragmentée. L'écran fatigue les yeux après 30 minutes. La batterie se vide en quelques heures si tu étudies intensément.
Sur ordinateur, c'est pire. Les onglets ouverts, les emails qui arrivent, Slack qui clignote, YouTube à portée de clic. L'apprentissage demande de la concentration soutenue, mais nos outils numériques sont conçus pour la fragmentation de l'attention.
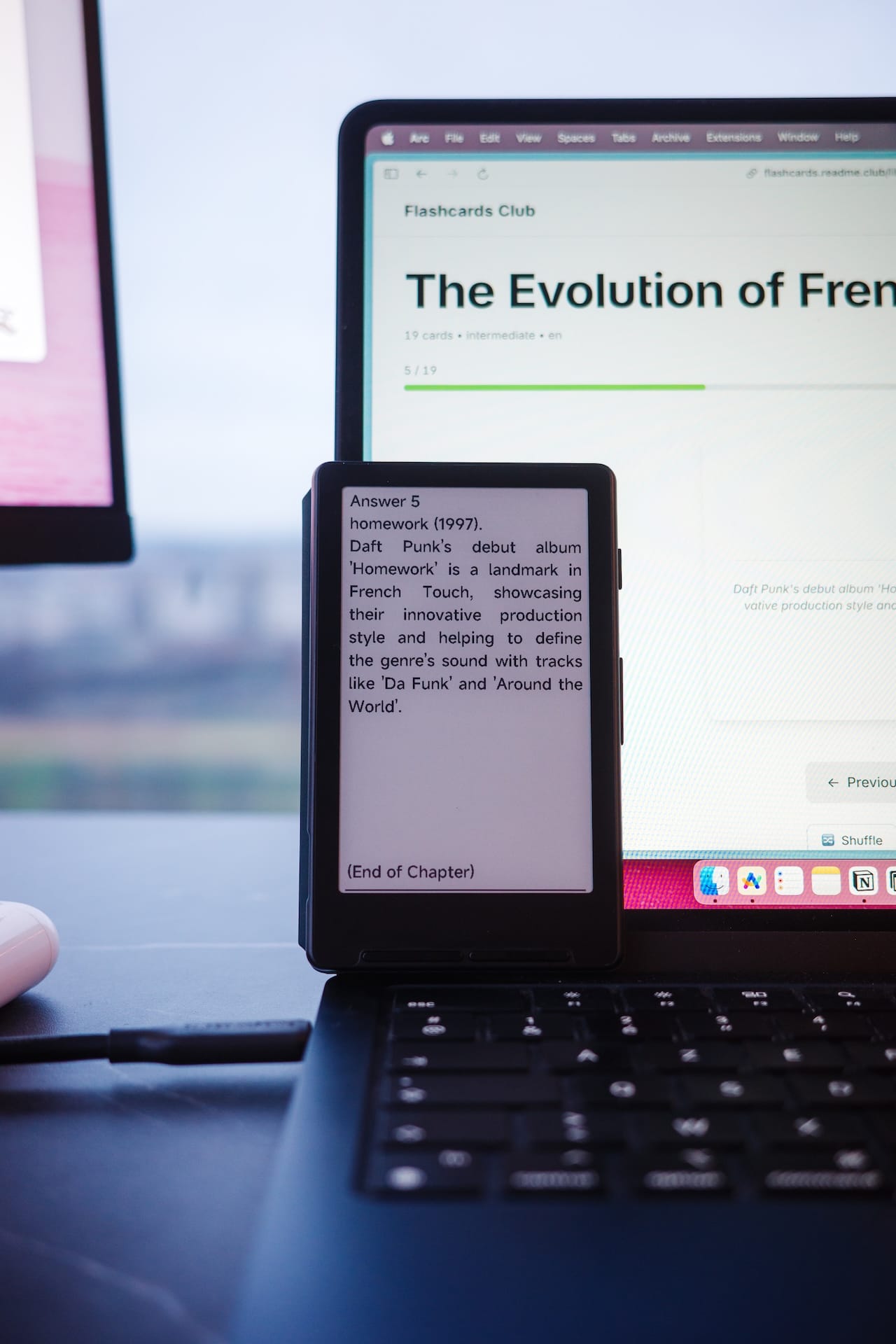
Les liseuses offrent exactement l'inverse. Pas de notifications. Pas de multitasking. Un écran qui ne fatigue pas et qui fonctionne en plein soleil. Une autonomie qui se compte en semaines. C'est le support idéal pour l'apprentissage qui demande de la régularité et de la concentration.
Le format EPUB est ouvert, standardisé, et fonctionne sur tous les devices. Si tu crées un EPUB correct, il s'affichera sur un Kindle, un Kobo, un Boox, un PocketBook. Pas besoin de développer pour iOS, Android, web. Un seul format, universel.
L'idée de Flashcards Club tenait en une phrase : générer des EPUB de flashcards optimisés pour e-ink, avec du contenu créé par IA selon les besoins de l'utilisateur.
Le MVP : faire le strict minimum qui fonctionne
Fin octobre, j'ai posé les bases. Pas de plan détaillé, pas de specs exhaustives. Juste l'essentiel pour valider l'hypothèse : est-ce que des gens veulent des flashcards au format EPUB ?
Le MVP tenait en quelques écrans :
- Un formulaire : thème, niveau de difficulté, langue, nombre de flashcards
- Une génération via OpenAI (gpt-4o-mini)
- Un fichier EPUB téléchargeable
- Aucun système de comptes, aucun paiement, aucune limitation
Le stack technique était volontairement simple. Astro pour le frontend (SSR/SSG, rapide, pas de JavaScript inutile côté client), Supabase pour stocker les générations, OpenAI pour créer le contenu, JSZip pour construire les EPUB.
Pourquoi Astro et pas Next.js ? Parce que je voulais un site rapide, léger, sans hydratation JavaScript côté client pour des pages qui sont essentiellement statiques. Astro fait exactement ça. Tu codes en TypeScript, tu utilises des composants, mais le résultat est du HTML/CSS pur côté client. Pour un outil comme Flashcards Club, c'est parfait.
Le choix de JSZip pour générer les EPUB mérite une explication. Il existe des bibliothèques EPUB toutes faites en JavaScript, mais elles sont souvent complexes, mal maintenues, ou trop opaques. Le format EPUB n'est rien d'autre qu'un fichier ZIP avec une structure XML spécifique. JSZip permet de créer cette structure à la main, fichier par fichier. C'est plus de boulot au départ, mais tu contrôles exactement ce qui est généré. Quand tu vas debugger pourquoi ton EPUB plante sur un Kindle mais pas sur un Kobo, cette transparence devient précieuse.
La structure d'un EPUB, c'est ça :
mimetype (non compressé, doit être le premier fichier)
META-INF/container.xml (structure de base)
OEBPS/content.opf (manifest et spine, le cœur de l'EPUB)
OEBPS/cover.xhtml (la couverture)
OEBPS/chapter1.xhtml (les contenus)
OEBPS/chapter2.xhtml
OEBPS/toc.ncx (table des matières)
Chaque flashcard devient un chapitre. Question sur une page, réponse sur la suivante. Simple. Le lecteur tourne les pages comme dans un livre, mais avec un contenu structuré pour la mémorisation.
Côté OpenAI, le prompt était direct. Je demandais un JSON strict avec un format précis :
{
"title": "Titre descriptif",
"flashcards": [
{
"question": "La question",
"answer": "La réponse",
"explanation": "Explication détaillée (2-4 phrases, max 125 mots)",
"difficulty": "beginner | intermediate | advanced"
}
]
}
Le titre est généré par l'IA, pas fourni par l'utilisateur. Ça évite les "mes flashcards" ou "test vocab" et ça donne des titres descriptifs qui ont du sens dans une bibliothèque de liseuse.
Première version du MVP fin octobre. Je l'ai testée sur mon Xteink X4. Ça fonctionnait. L'EPUB s'ouvrait, les flashcards s'affichaient, le format était lisible. J'ai partagé le lien à quelques personnes pour tester.

Beta : quand la théorie rencontre la réalité
Les premiers retours sont arrivés rapidement. Et ils étaient... instructifs.
Problème numéro un : les glyphes. Certains caractères s'affichaient en carrés sur Kindle. Les apostrophes, les guillemets typographiques, certains accents. Le problème venait de l'encodage. Les EPUB doivent être en UTF-8, mais certains caractères nécessitent des entités HTML (' pour l'apostrophe par exemple). J'ai ajouté une fonction de nettoyage qui décode puis ré-encode proprement tous les caractères spéciaux avant de les injecter dans l'EPUB.
Problème numéro deux : les couvertures. La première version générait des couvertures en image PNG via Canvas. Titre centré, police simple, fond uni. Sauf que Canvas dépend des fonts système, et quand tu génères une image côté serveur (sur Vercel), les fonts disponibles sont limitées. Résultat : sur certaines couvertures, les caractères s'affichaient en carrés. Encore.
J'ai d'abord essayé d'embarquer des fonts custom. Trop lourd, trop complexe, et toujours des problèmes selon les caractères. La solution a été contre-intuitive : abandonner les images pour les couvertures. J'ai créé des couvertures en XHTML/CSS pur. Pas d'image, juste du texte stylé. Avantage : compatibilité maximale, aucune dépendance aux fonts, et le rendu s'adapte à la liseuse. Inconvénient : c'est moins "joli" qu'une vraie cover design. Mais pour un outil d'apprentissage, la compatibilité prime sur l'esthétique.
Problème numéro trois : l'alignement. Sur certains devices, les flashcards n'étaient pas centrées, les marges étaient incohérentes, le texte débordait. Le CSS pour EPUB est capricieux. Tous les readers n'interprètent pas les styles de la même façon. J'ai passé des heures à tester sur différents devices (via Calibre en émulation, puis sur du vrai hardware) pour trouver un CSS minimal qui fonctionne partout. Pas de flexbox, pas de grid, juste des margins et du text-align. Ennuyeux, mais ça marche.
Pendant cette phase beta, j'ai aussi ajouté le cache. Si deux utilisateurs demandent les mêmes flashcards (même thème, même niveau, même langue, même nombre), pourquoi refaire un appel à OpenAI ? Je génère une clé de cache (theme|level|count|language), je vérifie si ça existe déjà dans Supabase, et si oui, je réutilise. Ça réduit les coûts OpenAI et ça accélère la génération. Le cache concerne aussi les EPUB : si le fichier est déjà généré, je le réutilise directement.
Un retour beta m'a fait ajouter une feature que je n'avais pas prévue : le mode "questions personnalisées". Certains utilisateurs ne voulaient pas que l'IA génère les questions. Ils avaient déjà leurs propres questions (extraites d'un cours, d'un manuel, d'un examen blanc) et voulaient juste que l'IA génère les réponses et explications. J'ai ajouté un deuxième mode dans le formulaire. Tu colles ta liste de questions, l'IA les utilise exactement telles quelles (instruction stricte dans le prompt : "Use the provided questions EXACTLY as written"), et elle génère les réponses associées. Ça a élargi les cas d'usage.

Fin novembre, la beta était stable. Les EPUB s'affichaient correctement sur Kindle, Kobo, Boox, PocketBook ... Les retours étaient positifs. Il était temps de passer à la version publique avec un modèle économique.
Le modèle économique : pourquoi one-time plutôt qu'abonnement
Dès le début, je savais que je ne voulais pas d'abonnement mensuel. Pour plusieurs raisons.
Première raison : le pattern d'usage. Les gens n'utilisent pas les flashcards de façon continue. Tu prépares un examen pendant deux semaines, tu génères 10 sets de flashcards, tu les révises intensément, puis tu n'y touches plus pendant des mois. Ou tu apprends une langue sur trois mois, puis tu mets en pause. Forcer un abonnement mensuel pour ce type d'usage, c'est frustrant pour l'utilisateur et ça génère du churn.
Deuxième raison : la subscription fatigue. Les gens sont saturés d'abonnements. Netflix, Spotify, Notion, ChatGPT, un SaaS pour le sport, un autre pour la compta, encore un pour la productivité. Chaque mois, ça s'accumule. Proposer encore un abonnement, même à 5€/mois, c'est ajouter une friction psychologique.
Troisième raison : la simplicité. Je ne voulais pas gérer des renouvellements automatiques, des relances par email, des problèmes de carte bancaire expirée, des demandes d'annulation. Le one-time payment élimine toute cette complexité.
Le modèle que j'ai choisi :
- Plan gratuit : 50 crédits par mois, régénérés automatiquement chaque mois. Un crédit = une flashcard. Tu peux générer un set de 15 flashcards, ça te coûte 15 crédits. Suffisant pour tester le service.
- Plan premium : 4,99€ pour une semaine de crédits illimités. Paiement unique, aucun renouvellement automatique. Tu paies, tu génères autant que tu veux pendant 7 jours, puis c'est terminé. Si tu as besoin de régénérer des flashcards six mois plus tard, tu repaies 4,99€.
Pourquoi une semaine et pas un mois ? Parce que la plupart des gens vont utiliser le service intensément sur une courte période. Tu prépares un examen, tu génères tous tes sets en 2-3 jours. Payer pour un mois entier n'a pas de sens. Une semaine est largement suffisant pour un usage intensif, et ça reste accessible en prix.
L'intégration Stripe a été directe. Stripe Checkout en mode payment (pas subscription), un webhook pour valider le paiement, et mise à jour des crédits côté Supabase. Pas de gestion de renouvellement, pas de logic complexe. Tu paies, tu as accès, c'est fini. 🥳
J'ai gardé un support legacy pour les subscriptions dans le code (visible dans les webhooks), mais le modèle principal est le one-time. Si je vois que des utilisateurs demandent un abonnement mensuel parce qu'ils utilisent le service régulièrement, je pourrais l'ajouter. Mais pour l'instant, le one-time colle parfaitement au besoin.
L'architecture technique : Astro, Supabase, Vercel
Le choix du stack n'était pas innocent. Je voulais un site rapide, facile à déployer, sans overhead inutile. Astro + Supabase + Vercel cochent toutes les cases.
Astro pour le frontend. SSR/SSG hybride, ce qui signifie que je peux générer des pages statiques pour le marketing (homepage, pricing, FAQ) et du SSR pour les pages dynamiques (génération, bibliothèque). Le JavaScript côté client est minimal. Pas de framework lourd qui hydrate toute la page. Résultat : un site qui charge en quelques centaines de millisecondes, même sur une connexion moyenne.
Supabase pour la base de données et l'authentification. PostgreSQL hébergé, avec une API REST et Realtime automatiquement générées. L'authentification se fait via Magic Link : tu entres ton email, tu reçois un lien, tu cliques, tu es connecté. Pas de mot de passe à gérer, pas de "mot de passe oublié", pas de hachage bcrypt. Simple et sécurisé.
La structure de la base de données est épurée :
- Table
users(gérée par Supabase Auth) - Table
fc_generations: stocke les flashcards générées, le cache, les métadonnées - Table
fc_credits: gère les crédits (free : 50/mois, premium : illimité)
Vercel pour l'hébergement. Déploiement automatique depuis GitHub, serverless functions pour les API routes, Vercel Blob Storage pour stocker les EPUB générés. Les Background Functions de Vercel permettent de lancer la génération de flashcards en asynchrone (appel OpenAI + génération EPUB) sans bloquer la requête HTTP initiale.
Le flow complet ressemble à ça :
- L'utilisateur remplit le formulaire sur
/generate - Validation côté serveur, consommation des crédits
- Création d'un job de génération en base
- Background Function lancée : vérification du cache, appel OpenAI si nécessaire, génération de l'EPUB, upload sur Blob Storage
- Pendant ce temps, le frontend fait du polling toutes les 3 secondes pour vérifier le statut
- Quand la génération est terminée, l'utilisateur reçoit un email avec l'EPUB en pièce jointe et peut le télécharger depuis la bibliothèque
Ce système asynchrone permet de ne pas bloquer l'utilisateur. La génération prend entre 10 et 30 secondes selon la taille du set. Si c'était synchrone, l'utilisateur attendrait devant un spinner pendant 30 secondes, ce qui est long pour une requête HTTP. Avec le polling, il voit la progression en temps réel et peut fermer la page s'il veut, l'email arrivera de toute façon.
Les défis techniques de l'EPUB
Générer un EPUB conforme, c'est plus complexe qu'il n'y paraît. Le format est standardisé (EPUB 3.0), mais l'interprétation varie selon les readers.
Le mimetype. Ce fichier doit être le premier dans l'archive ZIP, non compressé. Si tu le compresses ou si tu le mets ailleurs dans l'ordre des fichiers, certains readers refuseront d'ouvrir l'EPUB. JSZip permet de contrôler la compression fichier par fichier, donc j'ai désactivé la compression juste pour le mimetype.
Le container.xml. Ce fichier XML dans META-INF/ indique où se trouve le fichier OPF principal. Structure simple, mais obligatoire.
Le content.opf. C'est le cœur de l'EPUB. Il contient :
- Les métadonnées (titre, auteur, langue, date, identifiant unique)
- Le manifest (liste de tous les fichiers inclus dans l'EPUB)
- Le spine (ordre de lecture des chapitres)
Le spine est crucial. Il définit dans quel ordre les chapitres apparaissent. Si tu te trompes dans l'ordre, les flashcards seront mélangées.
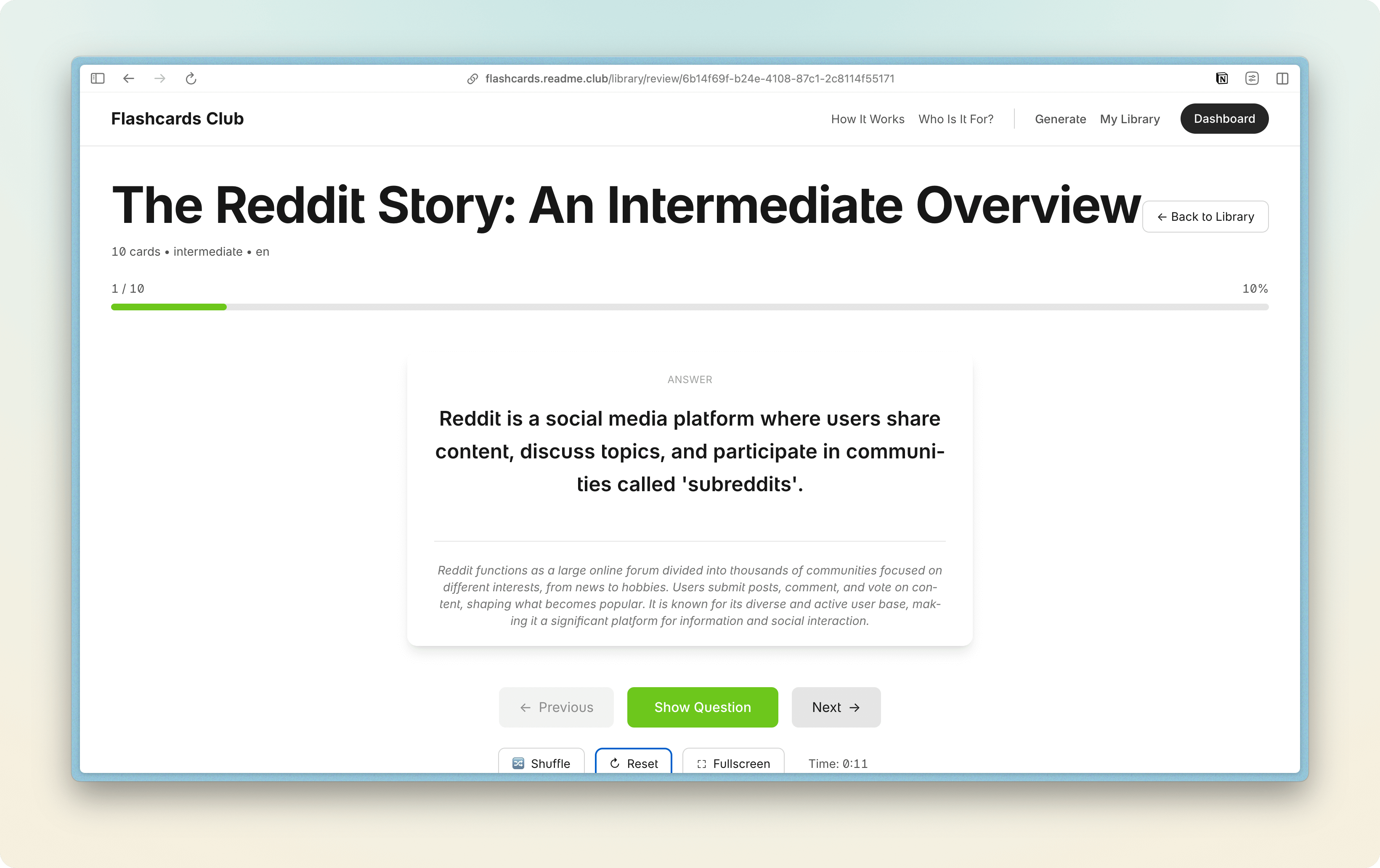
Les chapitres XHTML. Chaque flashcard est un fichier XHTML séparé. Question sur une page, réponse + explication sur la suivante. Le XHTML doit être bien formé (balises fermées, entités HTML correctes, namespace XHTML déclaré). Le moindre caractère mal encodé peut casser l'affichage.
Le toc.ncx. Table des matières au format NCX (spécifique EPUB 2, mais toujours supporté en EPUB 3 pour compatibilité). Certains readers l'utilisent pour la navigation.
Le CSS. Minimaliste. Taille de police raisonnable, marges cohérentes, alignement centré pour les flashcards. Pas de fantaisie. Les readers e-ink ont des capacités CSS limitées, et les utilisateurs peuvent de toute façon override les styles dans les réglages de leur liseuse.
Le plus gros piège : l'encodage. OpenAI renvoie du texte UTF-8, mais avec parfois des caractères qui nécessitent des entités HTML. Les apostrophes typographiques (' au lieu de '), les guillemets (" et "), les tirets cadratin (—). Si tu injectes directement ces caractères dans le XHTML sans les encoder, certains readers vont planter. La solution : une fonction de nettoyage qui décode d'abord tous les caractères (pour éviter le double encodage), puis ré-encode proprement en entités HTML.
function cleanText(text: string): string {
// Décoder d'abord (évite le double encodage)
const decoded = he.decode(text);
// Puis ré-encoder proprement
return he.encode(decoded, { useNamedReferences: false });
}
Avec JSZip, la génération finale ressemble à ça :
const zip = new JSZip();
// mimetype (non compressé, doit être en premier)
zip.file('mimetype', 'application/epub+zip', { compression: 'STORE' });
// container.xml
zip.file('META-INF/container.xml', containerXML);
// content.opf
zip.file('OEBPS/content.opf', contentOPF);
// cover
zip.file('OEBPS/cover.xhtml', coverXHTML);
// chapitres (flashcards)
flashcards.forEach((card, index) => {
zip.file(`OEBPS/chapter${index + 1}.xhtml`, generateChapterXHTML(card));
});
// toc.ncx
zip.file('OEBPS/toc.ncx', tocNCX);
// Génération du buffer
const buffer = await zip.generateAsync({ type: 'nodebuffer' });
Le buffer est ensuite uploadé sur Vercel Blob Storage, et l'URL est stockée en base. Quand l'utilisateur télécharge l'EPUB, on fetch depuis Blob Storage et on renvoie le fichier.
Les emails : Resend et la cohérence visuelle
L'email est un point de contact important. Magic Link pour se connecter, notification quand la génération est terminée. J'ai utilisé Resend pour l'envoi, avec des templates HTML.
Les emails sont sobres. Pas de design surchargé, juste le message essentiel. Pour le Magic Link : "Voici votre lien de connexion, il expire dans 15 minutes." Pour la notification de génération : "Votre set de flashcards est prêt, téléchargez-le ou consultez-le dans votre bibliothèque."
L'EPUB est attaché directement à l'email de notification. Ça évite d'avoir à se reconnecter sur le site si on veut juste récupérer le fichier. Tu reçois l'email, tu télécharges la pièce jointe, tu la transferts sur ta liseuse, c'est terminé.
Resend gère le SPF/DKIM/DMARC automatiquement, donc pas de problème de délivrabilité. Les emails arrivent dans la boîte principale, pas dans les spams.
Le lancement, bingo.
Début décembre, tout était en place. Le site fonctionnait, les EPUB s'affichaient correctement sur tous les devices testés, le système de paiement était opérationnel, les emails partaient bien. J'ai lancé le 12 décembre.
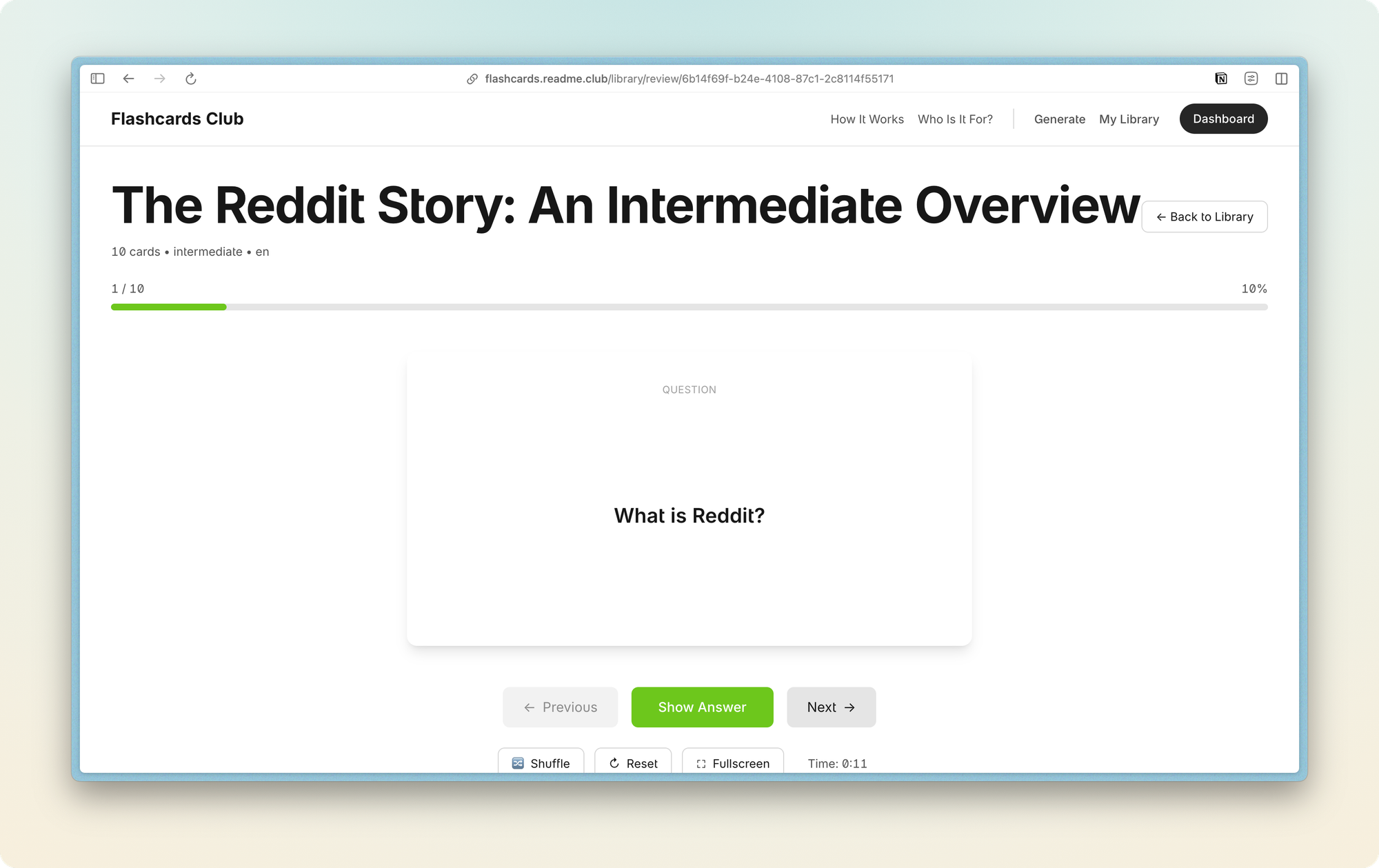
Pas de grosse campagne marketing. Un post LinkedIn, un post Reddit sur r/eink et r/SideProject, et c'est tout. L'objectif n'était pas de faire exploser le trafic, mais de valider que le produit répondait à un besoin réel.
Les premiers retours ont été positifs. Les utilisateurs de tablettes ont apprécié l'optimisation e-ink. Quelques questions sur le pricing (pourquoi 4,99€ par semaine ?), j'ai expliqué le modèle one-time et le pattern d'usage intensif sur courte période. Ça a fait sens. Sauf pour les trolls, et je les attendais.

Quelques bugs sont apparus en prod (évidemment). Un problème de cache qui ne se vidait pas correctement dans certains cas. Un souci d'affichage sur un vieux Kindle Paperwhite (première génération). Rien de bloquant, mais ça m'a rappelé qu'en beta, tu ne peux pas tester tous les cas.
Le plus satisfaisant : voir des gens utiliser l'outil pour des cas d'usage auxquels je n'avais pas pensé. Quelqu'un a généré des flashcards pour apprendre les capitales du monde. Un autre pour réviser des formules mathématiques. Un enseignant a créé des sets pour ses élèves. Le format EPUB universel permet ces usages variés sans avoir à adapter l'outil.
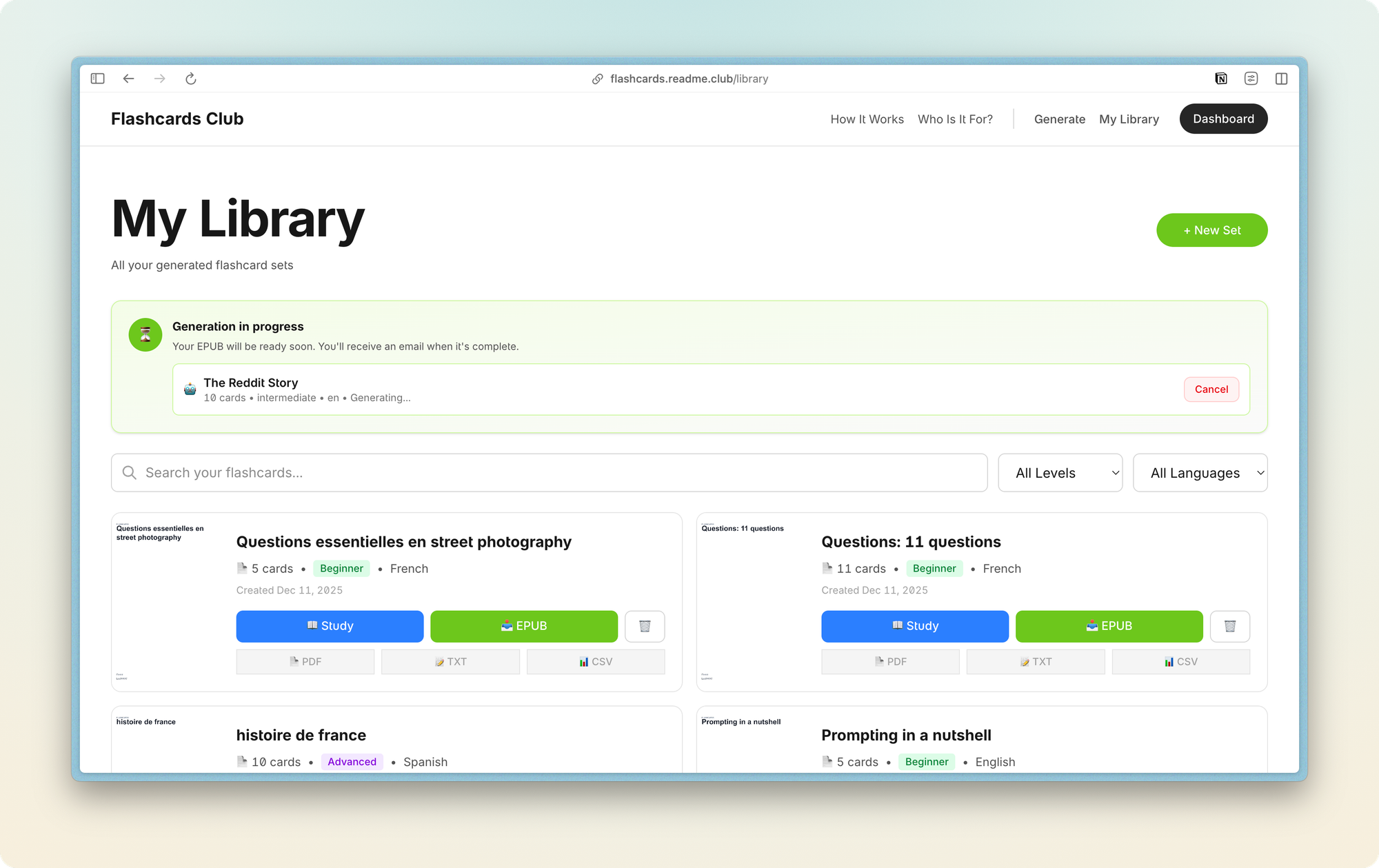
Ce qui reste à faire
Flashcards Club est opérationnel, mais ce n'est pas terminé. Il y a des features que je veux ajouter.
L'édition manuelle. Actuellement, si l'IA génère une flashcard avec une erreur ou une formulation que tu n'aimes pas, tu ne peux pas la modifier. Tu dois régénérer tout le set ou l'accepter tel quel. Je veux ajouter un éditeur qui permet de modifier les questions, réponses, explications avant de générer l'EPUB. Ça demande de stocker les flashcards en mode "brouillon", d'avoir une interface d'édition, et de régénérer l'EPUB à la demande. C'est faisable, mais ça ajoute de la complexité.
La consolidation d'EPUB. Certains utilisateurs génèrent plusieurs sets sur des thèmes proches (vocabulaire anglais niveau 1, niveau 2, niveau 3) et voudraient les fusionner en un seul EPUB. Techniquement, c'est juste une question de merger les chapitres et de reconstruire le manifest/spine. Mais il faut gérer les doublons, l'ordre, les métadonnées. Pas trivial, mais utile.
Les exports alternatifs. Le plan premium inclut déjà CSV/TXT/PDF, mais ils sont génériques. Certains utilisateurs voudraient exporter vers Anki (format .apkg). C'est un format propriétaire, mais il existe des libs pour le générer. Ça élargirait les usages. Et encore ...
Le mode étude en ligne. Actuellement, tu télécharges l'EPUB et tu le transfères sur ta liseuse. Mais certains utilisateurs n'ont pas de liseuse et voudraient réviser directement sur le site. J'ai ajouté un mode étude basique (affichage question/réponse avec un bouton "suivant"), mais il pourrait être plus évolué. Tracking des réponses correctes/incorrectes, statistiques, répétition espacée. Ça transformerait Flashcards Club en app de flashcards classique, ce qui n'est pas l'objectif initial, mais ça pourrait avoir du sens pour élargir l'audience.
La bibliothèque partagée. Il y a déjà une bibliothèque avec des sets pré-générés (vocabulaire courant dans différentes langues, concepts de base en programmation, etc.). Mais elle est limitée. J'aimerais permettre aux utilisateurs de partager leurs sets publiquement. Ça créerait une vraie bibliothèque communautaire. Le problème : modération, qualité, droits d'auteur si quelqu'un uploade du contenu protégé. Pas simple à gérer.
Les leçons de ce projet
Ce projet m'a rappelé quelques principes que j'applique depuis des années mais qu'on oublie parfois.
Commence petit. Le MVP de fin octobre était bancal, mais il fonctionnait. Il m'a permis de valider l'hypothèse et d'avoir des retours réels. Si j'avais passé trois mois à peaufiner tous les détails avant de lancer, j'aurais perdu du temps sur des features inutiles.
Les formats standardisés sont rarement aussi simples qu'ils en ont l'air. EPUB, c'est du XML et du XHTML. Ça paraît basique. Mais les subtilités (ordre des fichiers, encodage, compatibilité cross-readers) prennent du temps à maîtriser. Construire avec JSZip plutôt qu'utiliser une lib toute faite m'a coûté plus de temps au début, mais m'a donné un contrôle total sur le format.
Le pricing est un vrai sujet. J'ai hésité longtemps entre abonnement et one-time. J'ai fini par choisir one-time parce que ça collait mieux au pattern d'usage, mais ça reste une hypothèse. Si je vois que les utilisateurs reviennent régulièrement et préféreraient un abonnement mensuel moins cher, je pourrais pivoter. Le pricing n'est jamais figé.
L'authentification sans mot de passe, c'est confortable. Magic Link avec Supabase, c'est zéro friction. Pas de formulaire d'inscription à rallonge, pas de validation d'email avec lien de confirmation séparé, pas de "mot de passe oublié". Tu entres ton email, tu cliques sur le lien, tu es connecté. Simple.
Le cache réduit drastiquement les coûts. En cachant les appels OpenAI et les EPUB générés, je divise les coûts par 5 ou 10 selon les thèmes populaires. Si 50 personnes demandent "vocabulaire anglais niveau débutant", je ne paie qu'un seul appel OpenAI. Le cache est transparent pour l'utilisateur (il ne sait pas si son set est généré à la demande ou réutilisé), mais il change tout côté economics.
Tester sur du vrai hardware est indispensable. Calibre en mode émulation, c'est bien pour débugger rapidement. Mais rien ne remplace un vrai Kindle, un vrai Kobo, un vrai Boox. Les problèmes d'alignement, de glyphes, de CSS ne se révèlent que sur les vrais devices.
En bref.
Flashcards Club, c'est un outil. Mais c'est aussi une démonstration que les liseuses peuvent servir à autre chose que la lecture passive. L'e-ink est un support durable, confortable, qui favorise la concentration. Le format EPUB est ouvert et universel. Combiner les deux pour l'apprentissage, c'est évident en rétrospective, mais personne ne le faisait vraiment.
Il reste du boulot. Des features à ajouter, des bugs à corriger, des optimisations à faire. Mais l'essentiel est là. Le site est en ligne, les gens l'utilisent, les retours sont positifs. Le reste viendra progressivement.
Pour tester, c'est ici : https://flashcards.readme.club/
Gratuit pour commencer, 4,99€ si tu veux aller plus loin. Aucun piège à abonnement. Juste un outil qui fait ce qu'il dit faire.
Et si tu as une liseuse qui prend la poussière, c'est peut-être l'occasion de lui donner une deuxième vie.



