ChatGPT chez vous : installer son IA sans cloud et sans payer.
Et si vous pouviez avoir votre propre LLM, chez vous, sans jamais envoyer vos données à l'extérieur ni sortir la carte bleue ?


"L'intelligence artificielle transforme notre rapport au travail et à l'information."
Ok, merci Captain Obvious.
Mais dépendre entièrement de services cloud soulève des questions légitimes : confidentialité des données, coûts croissants, dépendance technique. Une alternative émerge : installer et utiliser des modèles d'IA directement sur votre machine.
Cette approche n'est plus réservée aux experts. Des outils accessibles permettent aujourd'hui à tout professionnel de déployer localement des systèmes d'IA performants, sans compromettre la sécurité de ses données. Imaginez pouvoir analyser vos documents confidentiels, générer du contenu ou automatiser des tâches sans jamais quitter votre infrastructure.
Mais avant toute chose : comprendre les tailles de modèles.
La performance d'un modèle d'IA se mesure principalement par son nombre de paramètres, exprimé en milliards (B pour billion en anglais). Un modèle 1B compte 1 milliard de paramètres, un modèle 7B en compte 7 milliards.
Plus ce nombre est élevé, plus le modèle est "intelligent" mais aussi plus gourmand en ressources. Concrètement, un modèle 1B (2 GB de RAM) répond rapidement mais de façon basique, parfait pour des tâches simples. Un modèle 7B (14 GB de RAM) offre un raisonnement plus sophistiqué et une meilleure compréhension du contexte, idéal pour l'analyse et la rédaction.
Un modèle 70B (140 GB de RAM) rivalise avec les meilleures IA cloud mais nécessite une configuration dédiée. Le choix dépend de l'équilibre souhaité entre qualité des réponses, vitesse d'exécution et ressources disponibles sur votre machine.
Ok, pourquoi choisir l'IA locale ?
Confidentialité totale des données
Vos documents, conversations et analyses restent sur votre infrastructure. Aucun transfert vers des serveurs tiers, aucun risque de fuite ou d'exploitation commerciale de vos informations sensibles.
Prenons l'exemple d'un cabinet d'avocats qui souhaite analyser des contrats pour identifier des clauses problématiques. Avec une solution cloud, chaque document transite par des serveurs externes, créant un risque juridique et déontologique. En local, l'analyse se fait en circuit fermé : les contrats restent dans les murs du cabinet, les requêtes ne sortent pas du réseau interne.
Indépendance économique
Fini les factures mensuelles qui s'envolent avec l'usage. Une fois votre système installé, les coûts se limitent à l'électricité consommée. Pour un usage intensif, l'amortissement peut être rapide.
Considérez une équipe qui utilise l'IA pour rédiger des contenus. Avec des tarifs cloud qui peuvent atteindre 50 € par mois par utilisateur, une équipe de dix personnes représente 6 000 € par an. L'investissement dans un serveur local devient rapidement rentable, tout en offrant une puissance dédiée et un usage illimité.
Cette économie libère aussi l'usage : plus de calculs de coûts avant chaque requête, plus de bridage par les quotas. Vous pouvez expérimenter, itérer et utiliser votre IA aussi intensivement que nécessaire.
Contrôle technique complet
Vous choisissez vos modèles, paramétrez leurs comportements, et n'êtes pas soumis aux limitations ou modifications imposées par les fournisseurs cloud. Pas de quotas, pas de bridage, pas de changements subis de politique tarifaire.
Un développeur peut ainsi personnaliser finement les réponses de son assistant IA selon les standards de codage de son entreprise. Il configure des prompts système spécifiques, ajuste la créativité selon le type de tâche, et intègre ses propres bases de connaissances techniques. Impossible avec une API externe qui impose ses règles.
Cette liberté s'étend au choix des modèles. Vous pouvez tester différentes approches :
- Un modèle rapide pour les tâches courantes
- Un modèle spécialisé pour l'analyse de code
- Un autre pour la rédaction créative
- ...
Et basculer selon vos besoins sans contrainte tarifaire. 🥳
Performance prévisible
Pas de latence réseau, pas de surcharge serveur aux heures de pointe. Vos ressources locales garantissent une réactivité constante.
Cette différence se ressent concrètement : votre requête d'analyse de document s'exécute en 2-3 secondes localement, contre 10-15 secondes en cloud aux heures d'affluence. Si votre machine suit évidemment.
Cette réactivité transforme l'outil en véritable assistant de travail plutôt qu'en simple gadget occasionnel.
Les outils essentiels
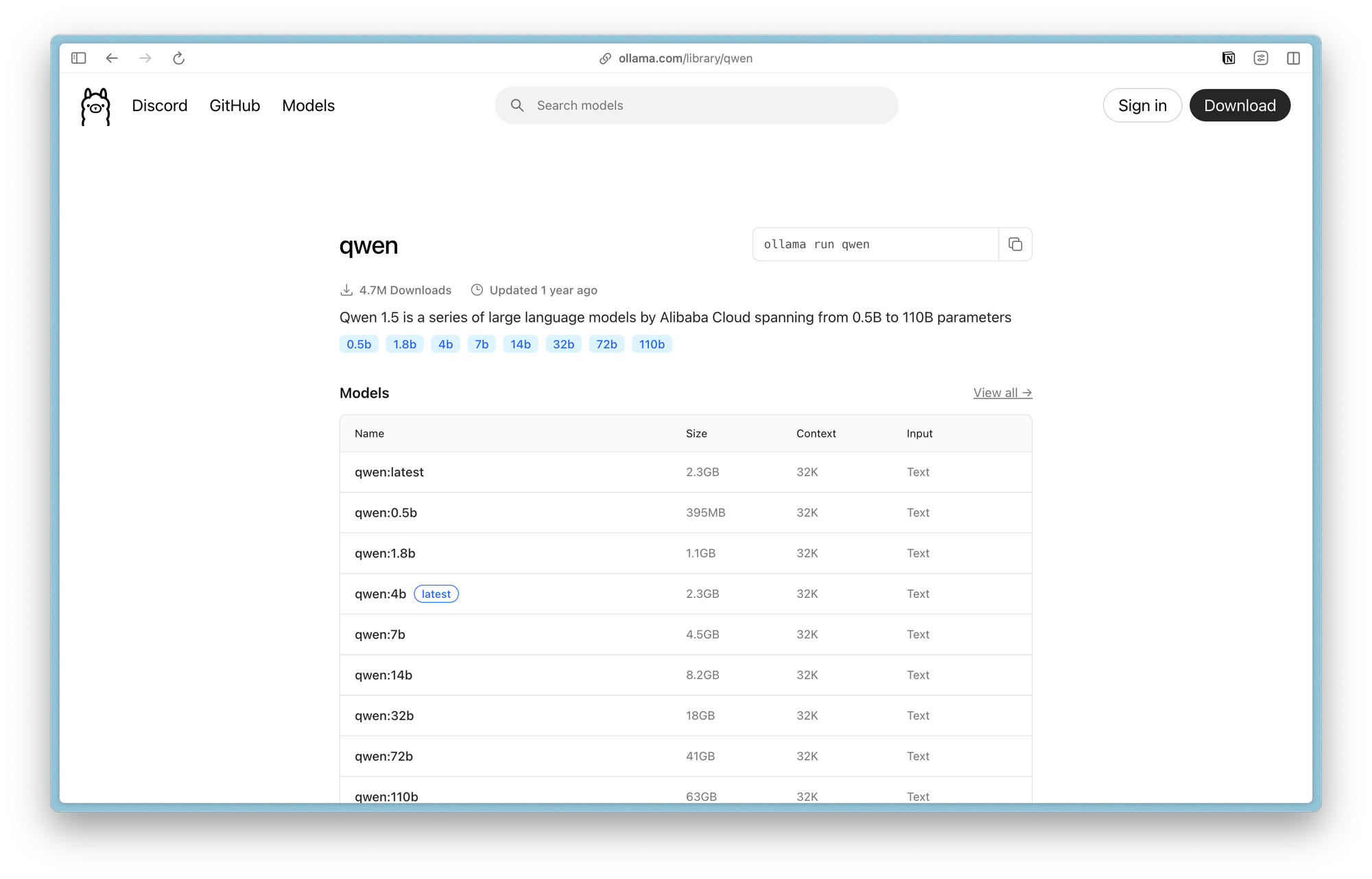
Ollama : le gestionnaire de modèles
Ollama simplifie drastiquement l'installation et l'utilisation de modèles d'IA. Cette solution open source gère automatiquement le téléchargement, l'optimisation et l'exécution des modèles sur votre machine.
Concrètement, Ollama fonctionne comme un "App Store" pour modèles d'IA. Vous tapez ollama pull llama3.2, et le système télécharge, configure et optimise automatiquement le modèle selon votre matériel. Pas de compilation manuelle, pas de configuration de dépendances - tout fonctionne immédiatement.
L'outil gère intelligemment vos ressources : il charge les modèles en mémoire quand vous les utilisez et les libère automatiquement pour économiser la RAM.
Sur un MacBook Air avec 16 GB de mémoire, vous pouvez faire tourner plusieurs modèles selon vos besoins sans saturer le système. C'est ce que je fais 😉
Points forts :
- Installation en une commande
- Catalogue de modèles prêts à l'emploi
- Optimisation automatique selon votre matériel
- API REST pour l'intégration
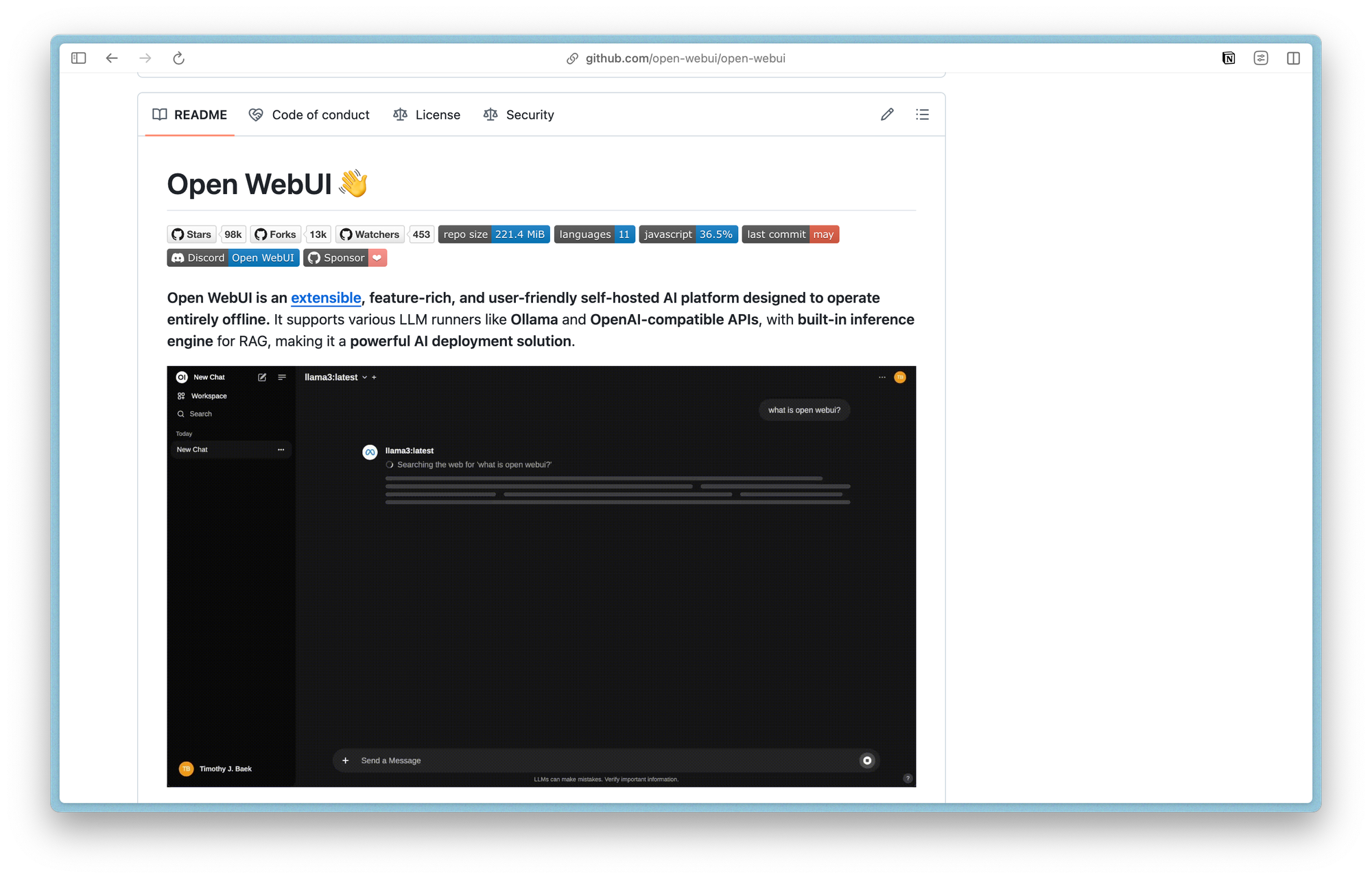
Open WebUI : l'interface utilisateur
Open WebUI propose une interface web élégante pour interagir avec vos modèles locaux. Plus qu'un simple chat, il intègre la gestion documentaire et les fonctionnalités RAG (Retrieval-Augmented Generation).
L'interface ressemble à ChatGPT mais tourne entièrement sur votre machine. Vous créez des conversations thématiques, sauvegardez vos échanges importants, et partagez des modèles configurés avec vos collègues. Un responsable marketing peut ainsi créer un modèle "Rédaction newsletter" avec des prompts personnalisés et le partager avec son équipe.
La gestion multi-utilisateurs permet de déployer l'outil dans une équipe tout en conservant la confidentialité. Chaque utilisateur accède à ses propres conversations et documents, mais peut utiliser les modèles partagés configurés par l'administrateur.
Fonctionnalités clés :
- Interface de chat intuitive
- Gestion multi-utilisateurs
- Intégration de bases documentaires
- Personnalisation des prompts système
Le RAG : enrichir les réponses
Le RAG permet à votre IA de puiser dans vos documents pour répondre avec précision à des questions spécifiques à votre domaine. Vos rapports, notes et documentation deviennent accessibles via une interface conversationnelle.
Imaginez un consultant qui accumule des études sectorielles, des rapports clients et des analyses concurrentielles. Avec le RAG, il peut demander : "Quelles sont les tendances émergentes dans le secteur automobile selon nos dernières analyses ?" Le système parcourt automatiquement ses documents, identifie les passages pertinents et synthétise une réponse documentée.
Cette approche transforme une montagne de documents en assistant intelligent. Plus besoin de se souvenir dans quel fichier se trouve telle information - l'IA retrouve et contextualise l'information pour vous.
Installation pratique
Configuration matérielle recommandée
Pour une expérience optimale, votre matériel détermine largement les performances. La bonne nouvelle : l'IA locale fonctionne sur du matériel standard moderne.

Configuration minimale :
- Un MacBook Air M2 avec 16 GB de RAM
- Un PC portable récent avec 16 GB de RAM
- 50 GB d'espace de stockage libre
Configuration recommandée :
- MacBook Pro M3 avec 32 GB de RAM
- PC avec processeur récent (Intel i7 ou AMD Ryzen 7) et 32 GB de RAM
- Carte graphique dédiée (optionnel mais accélère significativement)
- 100 GB d'espace SSD libre
La RAM détermine la taille des modèles utilisables. Un modèle de 7 milliards de paramètres consomme environ 14 GB en fonctionnement, un modèle de 13 milliards environ 26 GB. Une carte graphique accélère significativement la génération - comptez 3-5 fois plus rapide qu'avec le processeur seul.

Installation directe d'Ollama
L'installation d'Ollama se fait en quelques minutes sur tous les systèmes d'exploitation. Le processus est volontairement simplifié pour éviter les écueils techniques.
Téléchargez l'installateur depuis ollama.com et suivez l'assistant. Le programme s'installe comme n'importe quel logiciel classique sur macOS et Windows.
Une fois installé, Ollama fonctionne comme un service en arrière-plan. Il démarre automatiquement avec votre système et expose une API locale sur le port 11434. Vous pouvez vérifier son bon fonctionnement en ouvrant http://localhost:11434 dans votre navigateur.
Premier modèle
Le choix de votre premier modèle dépend de vos ressources et besoins. Commencez modestement pour appréhender le fonctionnement avant de passer à des modèles plus exigeants. Et là, tout se passe dans le terminal :
ollama pull llama3.2:3bCe modèle de 3 milliards de paramètres offre un bon équilibre entre performance et exigences matérielles. Il excelle dans les tâches de rédaction courante, la synthèse de documents et les questions-réponses générales.
Pour des besoins plus avancés, considérez :
mistral:7b: excellent pour l'analyse et le raisonnementcodellama:13b: spécialisé dans la programmationllama3.2:70b: performances maximales (nécessite beaucoup de RAM)
Le téléchargement prend quelques minutes selon votre connexion (bon, si vous êtes en 512 ...). Ollama gère automatiquement la vérification d'intégrité et l'optimisation selon votre matériel.
Test de fonctionnement
Lancez votre première conversation pour vérifier que tout fonctionne :
ollama run llama3.2:3b
Vous obtenez une interface de chat dans le terminal. Testez avec quelques questions pour évaluer la réactivité et la qualité des réponses. Tapez /bye pour quitter la session.
Cette étape valide votre installation et vous donne un premier aperçu des capacités. Notez le temps de réponse et la pertinence des réponses pour calibrer vos attentes.
Open WebUI : l'interface web
Pour une utilisation confortable, installez Open WebUI qui offre une interface graphique moderne et des fonctionnalités avancées.
Installation sans Docker :
pip install open-webui
open-webui serve
Si Python n'est pas installé sur votre système, téléchargez-le depuis python.org. Open WebUI nécessite Python 3.8 minimum.
Accédez ensuite à http://localhost:8080 dans votre navigateur. Lors du premier accès, créez un compte administrateur en fournissant nom, email et mot de passe. Cette étape configure votre instance personnelle.
L'interface se connecte automatiquement à Ollama et détecte vos modèles installés. Vous pouvez immédiatement commencer à discuter avec une interface plus agréable que le terminal.
Mise en place du RAG
Création d'une base documentaire
Le RAG transforme vos documents en base de connaissances interrogeable. Cette fonctionnalité distingue votre IA locale des assistants génériques en lui donnant accès à votre expertise spécifique.
Dans Open WebUI, naviguez vers "Workspace" puis "Knowledge". Cliquez sur "+" pour créer une nouvelle base. Donnez-lui un nom explicite comme "Documentation technique" ou "Analyses sectorielles".
Une fois créée, alimentez votre base en glissant-déposant vos documents. Open WebUI supporte PDF, Word, texte, et même des pages web. Le système analyse automatiquement le contenu, l'indexe et le prépare pour la recherche sémantique.
Configuration du modèle RAG
Créez maintenant un modèle qui combine votre IA de base avec votre documentation. Dans "Workspace > Models", cliquez sur "+" pour créer un nouveau modèle.
Sélectionnez :
- Modèle de base : llama3.2:3b (ou celui de votre choix)
- Base documentaire : la "Knowledge" que vous venez de créer
- Paramètres de recherche : nombre de documents à récupérer (3-5 par défaut)
Personnalisez le prompt système pour orienter les réponses. Par exemple : "Tu es un assistant spécialisé dans l'analyse financière. Réponds toujours en te basant sur les documents fournis et cite tes sources."
Cette configuration crée un modèle hybride : la capacité de raisonnement de l'IA générale enrichie par votre expertise documentaire spécifique.
Test et affinement
Testez votre modèle RAG avec des questions précises relatives à vos documents. Commencez par des requêtes dont vous connaissez la réponse pour valider la pertinence.
Observez la qualité des réponses et ajustez les paramètres :
- Augmentez le nombre de documents récupérés si les réponses manquent de contexte
- Affinez le prompt système si les réponses ne respectent pas le ton souhaité
- Enrichissez votre base documentaire si certains sujets restent mal couverts

Cas d'usage concrets
Analyse documentaire intelligente
Indexez vos rapports, contrats et procédures. Interrogez votre base documentaire en langage naturel pour retrouver instantanément l'information pertinente. Plus besoin de fouiller manuellement dans des centaines de fichiers pour retrouver une clause spécifique ou une analyse particulière.
Assistant de rédaction personnalisé
Utilisez votre IA comme assistant de rédaction, avec accès à votre style et vos références habituelles. Générez des ébauches, reformulez des passages, synthétisez des documents. L'IA apprend de vos écrits précédents pour adopter votre ton et respecter vos standards.
Support technique automatisé
Créez une base de connaissances technique interrogeable. Vos équipes accèdent rapidement aux procédures, dépannages et bonnes pratiques via une interface conversationnelle. Transformez vos manuels techniques en assistant interactif disponible 24h/24.
Veille et synthèse automatisées
Alimentez régulièrement votre système avec des articles, études et rapports sectoriels. Demandez des synthèses thématiques ou des analyses comparatives. L'IA analyse l'ensemble de votre veille et en extrait les tendances significatives.
Analyse de données métier
Connectez votre IA à vos bases de données pour analyser tendances et patterns. Posez des questions en langage naturel sur vos données de vente, vos métriques de performance ou vos indicateurs qualité.
Optimisation et personnalisation
Choix du modèle selon l'usage
Vous pouvez installer plusieurs modèles et les utiliser selon le contexte. Un consultant peut utiliser un modèle léger pour les échanges courants et basculer vers un modèle plus lourd pour l'analyse approfondie de dossiers clients, sans contrainte tarifaire.
Paramétrage fin des réponses
Open WebUI permet de personnaliser finement le comportement de vos modèles pour qu'ils s'adaptent parfaitement à votre style de travail.
Température (créativité) :
- Basse (0.1-0.3) : réponses factuelles et cohérentes
- Moyenne (0.4-0.7) : équilibre créativité/précision
- Haute (0.8-1.0) : créativité maximale pour le brainstorming
Prompts système personnalisés : Définissez le rôle et le style de votre assistant selon vos besoins spécifiques. L'IA adopte alors le comportement souhaité de manière constante.
Intégration professionnelle
L'API REST d'Ollama permet d'intégrer votre IA locale dans vos applications existantes. Cette capacité d'intégration ouvre des possibilités infinies d'automatisation sans dépendance externe.

Maintenance et évolution
Sauvegarde intelligente
Votre système d'IA locale contient trois types de données nécessitant des stratégies de sauvegarde différenciées.
Les modèles IA : Ces fichiers volumineux changent peu une fois téléchargés. En cas de panne, vous pouvez les retélécharger, mais une sauvegarde locale accélère la restauration.
Vos bases documentaires : Plus critiques car uniques, elles contiennent votre expertise propriétaire. Automatisez leur sauvegarde vers un support externe ou un cloud personnel chiffré.
Configurations personnalisées : Exportez régulièrement vos modèles personnalisés et prompts système. Ces réglages représentent des heures de fine-tuning.
Mise à jour du système
L'écosystème IA locale évolue rapidement. Planifiez des mises à jour régulières pour bénéficier des améliorations de performance et des nouveaux modèles.
Ollama publie régulièrement des versions optimisées apportant souvent des gains de performance significatifs. Les nouveaux modèles surpassent généralement leurs prédécesseurs tout en étant plus efficaces.

Avantages stratégiques
Égalité des chances technologique
L'IA locale remet tous les utilisateurs au même niveau. Une PME peut désormais accéder aux mêmes capacités qu'une multinationale, sans contrainte budgétaire prohibitive. Cette démocratisation transforme les rapports de force concurrentiels.
Plus de disparité entre ceux qui peuvent payer des abonnements premium et les autres. Avec l'IA locale, la seule limite devient votre capacité à configurer et utiliser efficacement l'outil, pas votre budget.
Indépendance et sécurisation
Maîtriser son infrastructure IA garantit une continuité de service et une protection contre les changements de politique des fournisseurs externes. Plus de risque de voir vos coûts exploser du jour au lendemain ou vos fonctionnalités bridées.
Cette indépendance devient cruciale quand l'IA s'intègre dans vos processus critiques. Vous gardez le contrôle total de votre chaîne de valeur numérique.
Innovation sans contrainte
L'absence de limitations externes libère l'innovation. Vous pouvez expérimenter, tester de nouvelles approches et itérer rapidement sans vous soucier des quotas ou des coûts marginaux.
Cette liberté d'expérimentation accélère l'adoption et permet de découvrir des usages inattendus spécifiques à votre contexte.
En bref.
L'IA locale représente bien plus qu'une alternative technique aux solutions cloud. Elle incarne une philosophie : reprendre le contrôle de ses outils et de ses données à l'ère numérique.

Cette approche demande certes un investissement initial en temps et en ressources, mais elle offre en retour une autonomie stratégique précieuse. Dans un monde où la dépendance technologique devient un risque majeur, maîtriser ses outils d'IA devient aussi crucial que maîtriser ses moyens de production.
L'IA locale n'est plus un luxe technique réservé aux experts : c'est une opportunité accessible pour qui veut garder la maîtrise de son avenir numérique. Les outils existent, ils sont matures et simples à déployer. Il ne reste plus qu'à franchir le pas.
L'aventure commence par une simple commande : ollama pull llama3.2:3b. Derrière cette simplicité se cache une révolution : celle de l'IA démocratique, respectueuse de vos données et adaptée à vos besoins. Une révolution que vous pouvez déclencher dès maintenant, depuis votre bureau, en toute autonomie.
La question n'est plus de savoir si l'IA locale va s'imposer, mais à quelle vitesse vous allez l'adopter.
Car dans cette course à l'autonomie numérique, les premiers arrivés prendront une avance décisive sur leurs concurrents encore dépendants des solutions externes.



